
ML-SHARING Ep 4: Semi-Supervised Learning - một đứa con lai kỳ dị đầy thú vị ? 🧐
20/9/2024 By Daves Tran

Đây là phần một trong “collection” về chủ để “Semi-supervised Learning Classification Problem” - (dịch: Bài toán Phân loại với ý tưởng học “bán dám sát”).
Mở Đầu
Semi-Supervised Learning - What the heck is this ??
Đúng - đọc tên tiêu đề của bài viết này, bạn có thể biết chúng ta sẽ bàn về chủ đề gì ngày hôm nay - Khi mà tất cả các “beginner” mới chân ướt chân ráo bước vào chinh phục thế giới “khủng bố” của Machine Learning (ML), chưa hết ngỡ ngàng đến bàng hoàng vì chỉ hai bài toán cơ bản “Supervised Learning - SL - học có dám sát ” và “Unsupervised Learning - UL - học không có dám sát” , thì các nhà khoa học lại cho thêm nhiều phát kiến mới đi vào lòng đất với muôn vàn bài toán ML khác như “Semi-Supervised Learning (SSL - học bán dám sát)” làm cho những người học về ML cũng như những ai muốn đi tìm hiểu về chủ đề này cũng phải “đau đầu nhức não” thế nào - trong đó có cả mình 🤯.
Nhưng sau khi trải qua một khoảng thời gian “buốt não” cùng với đống papers về SSL, thì mình đã tóm tắt những gì mình biết một cách cơ bản để chuẩn bị cho các bạn đọc muốn nhảy vào “bài toán lạ lẫm, nhưng thú vị này”
Vậy trong bài viết này chúng ta sẽ cùng tìm hiểu về:
Semi-Supervised Learning (SSL) là gì ?
Tại sao SSL lại xuất hiện & Một số điều cơ bản về SSL
#Note: Trong bài này có thể đề cập đến nhiều khía cạnh kỹ thuật và các thuật toán, nhưng đã được tác giả tối giản hoá và chỉ còn giữ lại một số ý tưởng quan trọng (intuition) để phù hợp với số đông đọc giả, nhưng trong quá trình diễn giải có thể có sai sót - mong bạn đọc thông cảm và sẽ có đính kèm nguồn gốc của ý tưởng để bạn có thể tiếp tục tìm hiểu thêm
Cảm ơn bạn đã đọc chiếc Note này 📧.

1. Semi-Supervised Learning (SSL) là gì ?
Phần này sẽ là một chút review - nếu bạn đã có nền tảng cơ bản rồi thì bạn có thể skip đến phần SSL nhé (nhưng một chút Review sẽ chẳng hại gì mà phải không ?)
Một chút review với “Cửa hàng tạp hoá” 🛒
Trước khi chúng ta cùng bàn về SSL, thì chúng ta hãy cùng “review lại” một chút định nghĩa cơ bản về ML về các bài toán cơ bản nhé !
ML - Machine Learning (học máy) : là một nhóm bài toán thiết kế các hệ thống máy (Machine) có thể đưa ra quyết định (Decision Making) như con người trong một nhiệm vụ cụ thể thông qua quá trình huấn luyện & học hỏi (Learning) từ các đầu vào do người dùng đưa vào (còn gọi là Data - Dữ Liệu) - (Check Tập 1 để được xem ví dụ chi tiết)
Data là một thực thể mang thông tin (Information), và trong bài toán ML, đối tượng mà ML làm việc thường là các Data-point (điểm dữ liệu)
Một Data-point thông thường được cấu tạo với hai thành phần:
Phần thứ nhất - đầu vào (có khá nhiều tên: Observation, Input)
Phần thứ hai - đầu ra (Output, Label)
Để có thể hình dung ra - bạn có thể hình dung Data-point trong ML như một món hàng cụ thể tại một góc nhất định trong cửa hàng tạp hoá (Groceries) :
Từng món hàng trên kệ sẽ có hình dạng khác nhau (mang các đặc điểm - features) mà bạn có thể nhìn thấy trực tiếp - Đây là phần input (hay observation)
Nhưng mỗi món hàng được gắn một cái mác (ghi thông tin về giá cả & xuất xứ món hàng, etc.) - Đây là label - nhãn (bạn có thể hình dung nó như “tên của dữ liệu”)

Data như các món hàng trong cửa hàng tạp hoá - Image Source: japantravel.navitime.com Tổng hợp nhiều món hàng (Các Data-points) tạo lên một kệ hàng - đây là ý nghĩa của Dataset (tập dữ liệu - tập hợp toàn bộ các data-point)
Trong các vấn đề ML giải quyết, thì có nhiều nhánh được chia nhỏ ra - và các nhánh này được đặt tên dựa trên đặc điểm của đầu vào (Các Data-points - điểm dữ liệu) đưa vào huấn luyện cho “cỗ máy” của bạn
Giả sử nếu quay lại với phép so sánh “cửa hàng tạp hoá” ở trên - bạn đang muốn thiết kế một con Robot tự động dán nhãn cho các mặt hàng. Thì bạn sẽ có hai ý tưởng để thiết kế cách thức con robot này hoạt động như sau:
Ý tưởng 1 - Supervised Learning (SL) - học có dám sát:
Bạn cho Robot hàng loạt món hàng (input) có kèm tên nhãn - và yêu cầu nó học quy luật giữa các “Labels” với mặt hàng tương ứng “Observation” - có sự dám sát (ràng buộc giữa nhãn với mặt hàng).
Ví dụ: Robot được đưa một loạt hình ảnh của những hộp sữa kèm với mức giá tương ứng (ví dụ: sữa “Dutch Lady” thì giá tầm 30 - 40 k VND). Kết quả là đưa cho Robot một hộp sữa chưa được dán tem giá, nhưng chỉ cần nhìn hiệu là “Dutch Lady” thì tự động nó sẽ cho một cái “nhãn” từ 30 - 40k VND)
Ý tưởng 2 - Unsupervised Learning (UL) - học không có dám sát:
Bạn đưa cho Robot hàng loạt các món hàng - input (Observation), nhưng chẳng có món nào có tem giá cả (Label) - và bạn mong cỗ máy dán nhãn của bạn sẽ tự tìm ra quy luật để gắn nhãn (label) với từng món hàng, một cách tự động (Không có ràng buộc) !
Ví dụ: Bạn đưa cho Robot một loạt các hộp sữa, nhưng bạn không dán nhãn cho nó về thương hiệu của các hộp sữa này, nhưng máy của bạn để ý tất cả các hộp sữa đều có cùng logo là “Dutch Lady” trên bao bì, thì sau một khoảng thời gian học từ dữ liệu- thì cỗ máy của bạn gán tất cả các hộp sữa bạn đã đưa nhãn “Dutch Lady”.


Ok - Vậy việc Review trên liên quan gì đến SSL !
Việc review một cách vô cùng “dài dòng” và “lê thê” như ở trên là để chuẩn bị cho các bạn một chút nền tảng để chúng ta tiếp cận với bài toán SSL (học bán dám sát).
Có lẽ để miêu tả một cách dễ hình dung với một ai mới nghe đến bài toán SSL lần đầu tiên - thì SSL (Semi-supervised Learning) là kết quả của sự kết hợp giữa SL và UL

Nói cụ thể ra - cỗ máy ML của bạn trong bài toán SSL thay vì chỉ được huấn luyện duy nhất trên tập dữ liệu 100% có hoàn toàn dán nhãn (labeled) - như SL hay 100 % không có nhãn như UL. Thì đầu vào của bạn sẽ có cả dữ liệu vừa có nhãn, và vừa không có nhãn.
Nhưng trong SSL - đa phần các điểm dữ liệu trong tập của bạn là các dữ liệu không được dán nhãn. (bạn có thể tham khảo hình bên dưới).

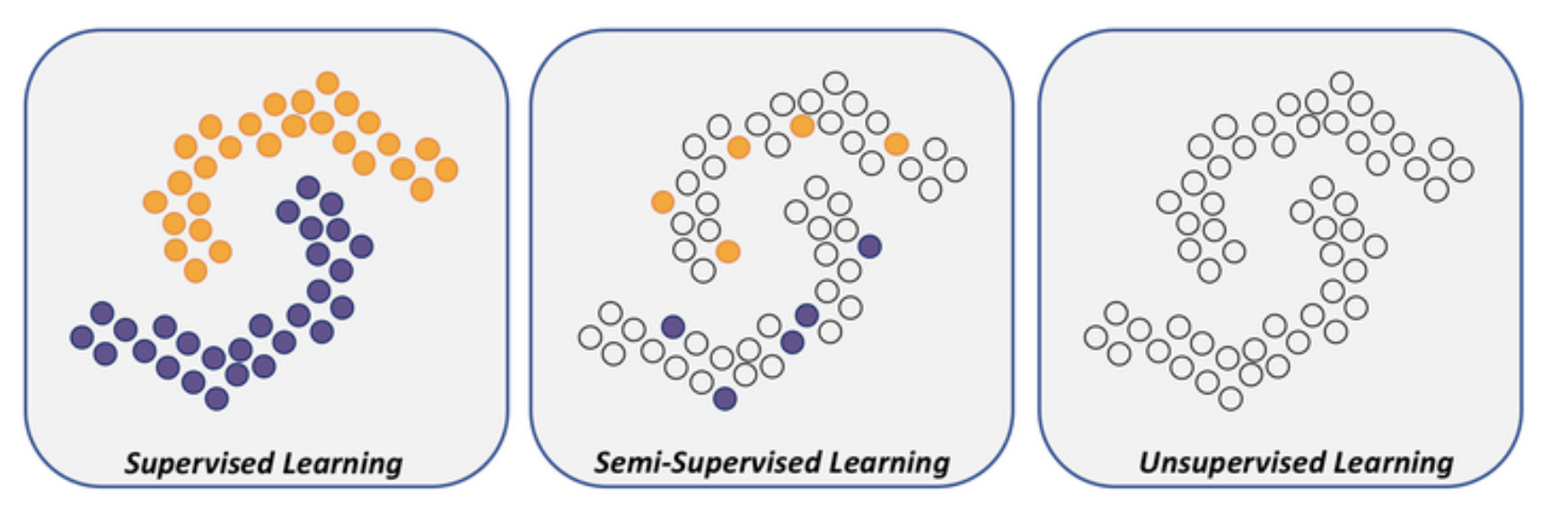
Để nói dễ dàng hơn, chúng ta có thể quay lại với ví dụ của cửa hàng tạp hoá trong phần bên trên. Nếu bạn muốn thiết kế Robot gán nhãn của bạn với ý tưởng SSL thì bạn có thể làm như sau:
Cho một loạt các hộp sữa - trong số đó có những hộp sữa gán tem giá từ 30 - 40k VND (rất ít), và một lượng lớn hộp sữa không có tem giá (label) gì cả.
Nhưng cỗ máy của bạn nhận diện các thương hiệu của các hộp sữa không có tem giá cũng khá gần với một số hộp sữa đã được dán tem (như một số hộp sữa “Dutch Lady” thường có nhãn là 35k VND)
Kết quả là máy của bạn tự học cứ gặp hộp sữa “Dutch Lady” là dám tem 35k vào hộp đó - mặc dù chỉ được đưa mỗi label có tem dán giá bán với số lượng ít ỏi.
2. Tại sao SSL lại xuất hiện & Một số điều cơ bản về SSL
Vậy đọc phần trên - nếu bạn nào tinh ý thì có thể hiểu mục đích của “bài toán SSL” này xuất hiện, nhưng nếu bạn nào chưa nhìn được thì mình xin phép giải thích.
Bản chất các dữ liệu trong tự nhiên (từ quá trình thu thập dữ liệu & lấy mẫu Sampling) là các dữ liệu không có dán nhãn (unlabeled dataset), và thường quá trình gán nhãn (labeling) thì lại phải có tác động của con người (từ trực tiếp gán nhãn hay thông qua các thuật toán tự động)
Nhưng với điều kiện có hạn trong đó có bao gồm !
Thuật toán gán nhãn & tìm kết nối giữa đầu vào với nhãn cần tài nguyên tính toán (Computational Resource) - khó mà mở rộng (Scale-up) và kiểm soát với kích cỡ toàn bộ dữ liệu khi tăng dần theo cấp số mũ:
Bạn có thể xem thử bài toán Clustering bằng thuật toán EM (tối đa hoá giá trị kỳ vọng) là một tiêu biểu ví dụ cho giới hạn này !
Tài nguyên con người có hạn - như về mặt năng lượng, và con người cũng có thể có lỗi (error) và vô tình đưa thiên kiên (bias) vào bộ dữ liệu qua nhãn.
Vấn đề về "lỗi do con người - human error” đủ gây thảm hoạ này thế nào thì bạn có thể tham khảo tập hai của series ML để tìm hiểu thêm (check tại đây) - hoặc cụ thể hơn bạn có thể tìm hiểu thêm bài báo của Liu năm 2023 về tầm quan trong của dữ liệu có nhãn với các tính an toàn của các mô hình LLM (mô hình ngôn ngữ lớn) - một sản phẩm của ML (Liu et al., 2023).
Trước tình huống với một lượng ít ỏi dữ liệu có nhãn & và lượng lớn các dữ liệu không có nhãn - thì các nhà khoa học đã biến “trong cái rủi có cái may” - và đã thử đặt ra câu hỏi:
Làm thế nào để có thể huấn luyện một mô hình ML trong điều kiện ít dữ liệu có nhãn, trong khi dữ liệu "vô nhãn" lại có quá nhiều ?Đó là mục đích của bài toán SSL xuất hiện. Gọi là nhóm các bài toán này là “bán dám sát - Semi supervised” bởi vì thay vì vứt bỏ toàn bộ các điều kiện ràng buộc như bài toán UL là dùng 100% dữ liệu không có nhãn và vứt cho “Cỗ máy” của bạn tự tìm ra đáp án, thì mô hình “machine” còn được “bố thí” lại một chút “manh mối về đáp án” từ số lượng ít ỏi dữ liệu có nhãn (labeled data), và phải tự học cùng với manh mối từ các dữ liệu không có nhãn (unlabeled).
Nhìn chung, câu chuyện của SSL có thể như một cách nhà khoa học “vượt khó” về bài toán nguồn cung hạn hẹp của dữ liệu cho bài toán gốc “Supervised Learning".
Ngoài ra một trong số những ứng dụng tiêu biểu và đáng kể tên SSL (hiện giờ cũng là ứng dụng phổ biến nhất) là bắt nguồn với bài toán phân loại dữ liệu (Classification problems) - cụ thể hơn là với dữ liệu ngôn ngữ tự nhiên - (van Engelen & Hoos, 2019), (Abney, 2002)
Nhiều điều cần lưu ý về SSL 😲 !
Nói chung để diễn tả ý tưởng chung của SSL - thì mình sẽ mượn lời của van Engelen & Hoos, 2019 để tóm tắt như sau:
Các thuật toán SSL được tạo nên dựa trên việc kết hợp 2 yếu tố “UL và SL”, nên thường chúng sẽ cố gắng cải thiện hiệu quả thông qua việc sử dụng thông tin liên quan đến 1 trong 2 yếu tố để bổ trợ khuyết thiếu cho yếu tố còn lại.
Bạn có thể hình dung SSL việc một đứa con được lai từ một người bố (mẹ) có khả năng làm việc có kỷ luật (SL) nhưng kém sáng tạo; và một người mẹ (bố) có tính sáng tạo (UL) nhưng thiếu kỷ luật, nên đứa con đó là sự kết hợp hài hoà - theo khuôn khổ và sáng tạo nhưng không bê bối và dập khuôn ✨
Theo bài báo của Engelen, cho rằng SSL chỉ thực sự có ích phải phụ thuộc vào bản chất của dữ liệu và thuật toán học được sử dụng
Về bản chất dữ liệu:
Dữ liệu vô nhãn - unlabeled được dùng huấn luyện phải có chứa “thông tin” hỗ trợ cho quá trình học của máy móc mà dữ liệu được gán nhãn (labeled) không có (Show),
Hay nếu dữ liệu có nhãn có sở hữu “thông tin” thì khó mà có thể tách ra và "dịch” cho máy hiểu được (Tell). (Tạm gọi đây là bài toán: “Show don’t Tell”)
Về bản chất của thuật toán:
Thuật toán SSL phải được thiết kế để tách ra các “thông tin chìm” từ các dữ liệu điểm không có nhãn để cung cấp kiến thức cho máy để cải thiện hiệu năng.
Nhưng làm thế nào, thì Engelen lại nói đây là một bài toán “khó không tưởng và đây mâu thuẫn”.
Do có nhiều ý tưởng và bàn luận về SSL đã được đề xuất, nhưng nhìn chung cũng khá là hỗn độn và chưa hoàn hảo, do đó mình chỉ tạm tóm lại ở một số ý chính mà mình thấy khá liên quan cho case-study với bài viết ML-sharing về chủ đề phân loại sắp tới. (còn cụ thể thế nào sự hỗn loạn này thế nào - mình nghĩ bạn nên thử đọc bài của van Engelen để tìm hiểu thêm).
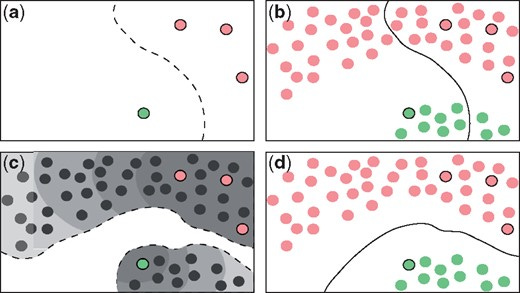
Inductive và Transductive Learning (2 kiểu học với bài toán “Show don’t Tell”)
Khái niệm về “Inductive - quy nạp” và “Transductive” là hai trường phái để thiết kế các hệ thống ML học khi kết hợp cả dữ liệu có nhãn và vô nhãn (không chỉ riêng bài toán SSL) - theo (Teksands , 2021)
Inductive cơ bản là cỗ máy học từ dữ liệu gán nhãn - sau đó nó tìm ra một cái “luật ngầm” để phân loại dữ liệu dựa trên việc “suy luận - reasoning” từ các đầu vào, sau đó các mẫu được đưa vào để liên tục phân loại (cả có nhãn hay không)
Transductive thì khác hơn: Thay vì tìm ra một quy luật rồi chụp mũ với mọi điểm (bản chất của quy nạp), thì máy sẽ học dựa vào một mẫu thử nhất định (là 1 tình huống cụ thể) khi huấn luyện - rồi áp dụng điều đã học trong tình huống này với mẫu kiểm tra (test) có cùng tình huống tương tự - Specific Train Case → Specific Test Case
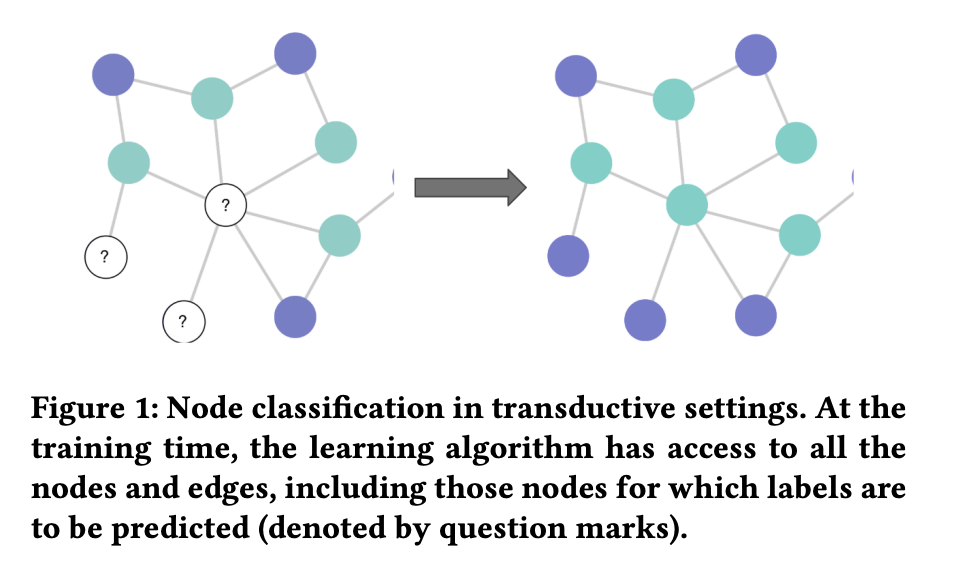
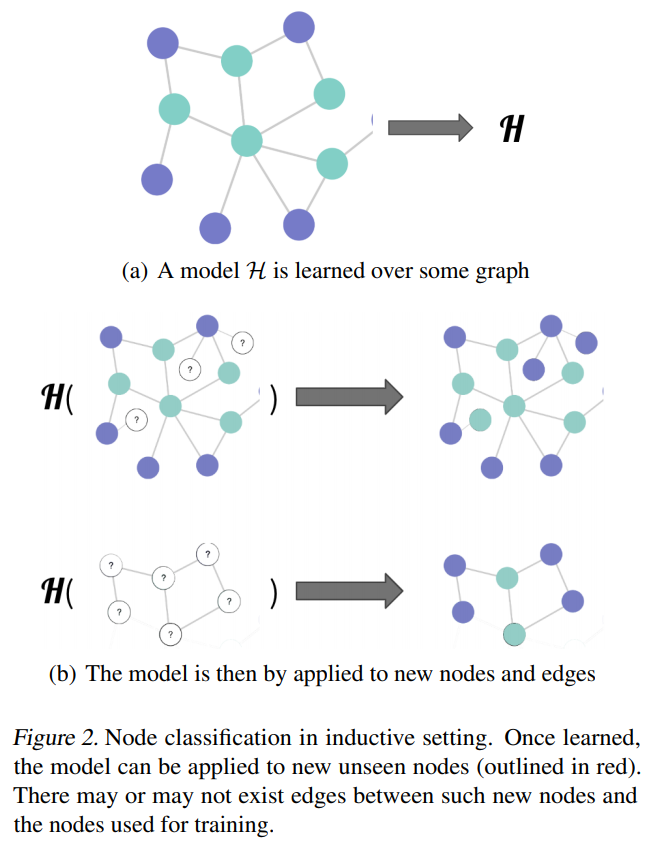
“Khi giải quyết một vấn đề cụ thể, đừng giải quyết một vấn đề tổng quát hơn như là một bước trung gian. Hãy cố gắng tìm ra câu trả lời mà bạn thực sự cần chứ không phải một câu trả lời tổng quát hơn.” - Vladimir Vapnik (source: Wikipedia)Wrapper Method’s - “tối cổ nhưng lợi hại” 😅
Phương pháp “Wrapper” được sắp vào là một phương pháp ML thuộc dòng Inductive như chúng ta đã nhắc ở bên trên - và theo van Engelen đã nhắc đến trong bài rằng đây là một trong số các phương pháp “tối cổ nhất”, nhưng vẫn đang sử dụng thịnh hành trong các bài toán phân loại bằng ý tưởng SSL.
Ý tưởng của Wrapper Method là bạn có n chiếc máy phân loại (n classifiers) - tất cả chưa được học gì cả
Từng máy trong n máy được huấn luyện trên 2 loại dữ liệu:
Dữ liệu gốc đã được gắn nhãn
Dữ liệu “Vô nhãn” - unlabeled, nhưng tất cả sẽ được gán cho một cái “bí danh - alias” tạm thời, và cái bí danh này sẽ luôn được cập nhập bằng mô hình sau lần học mới nhất (latest training iteration)
Dựa vào 2 kiểu dữ liệu (dữ liệu với tên thật, và dữ liệu dùng bí danh) - thì Wrapper Method cũng có 2 bước trong thiết kế một mô hình phân loại theo ý tưởng SSL:
Bước 1: Training (Huấn luyện) - máy phân loại được học bằng dữ liệu mang tên thật và dữ liệu mang “Alias”
Bước 2: Pseudo-Labeling (Cập nhập bí danh) - máy phân loại sẽ dùng lượng kiến thức mà nó đã được học mới nhất để sửa các “Alias” cho các dữ liệu “vô nhãn”, và để bước vào lần huấn luyện mới.
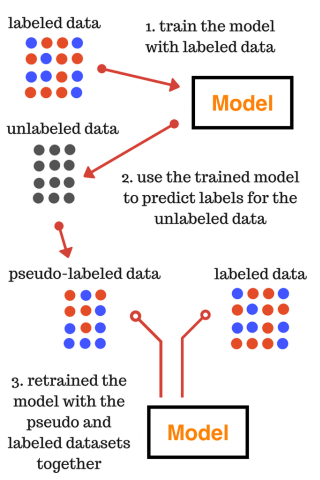
Self-training , Co-training và bài toán phân loại 🕵🏻♂️:
Ở phần trên mình nói là phương pháp Wrapper có sử dụng đến n - máy phân loại (Classifier"), nhưng không có nói rõ n là một giá trị như thế nào, và đây chính là mấu chốt cho 2 kiểu vấn đề con (sub-problem) của Wrapper Method: Self-training và Co-training.
Self-training: là phương pháp để thực hiện Pseudo-labeling đơn giản nhất - chỉ cần dùng một máy phân loại (n=1) vừa học vừa gán nhãn giả cho dữ liệu không mang nhãn - đây là ý tưởng của Yarowsky (1995) sơ khởi nhất về SSL cho bài toán phân loại. (Tương ứng với hình trên)
Quá trình này ban đầu huấn luyện với toàn bộ dữ liệu có nhãn
Sau đó thu được mô hình - và thử dùng với dữ liệu không nhãn → chọn trong số dữ liệu được gán “bí danh” những cái tự tin là chính xác nhất để thêm vào tập dữ liệu, những điểm còn lại không đuợc chọn bị xoá tên và để gán lần tiếp thep
Lặp lại bước trên cho đến khi tập dữ liệu không được gán nhãn không còn điểm nào
Co-training (Chủ đề của tuần tới): Đây là phiên bản mở rộng của bài toán Self-training, khi có nhiều hơn một máy phân loại (n ≧ 2), và còn lại ý tưởng của thuật toán cũng khá tương tự so với Self-training (như cụ thể thế nào thì bạn hãy đợi số tiếp theo của ML-sharing để biết nhé 😉)
Lời Bình Cuối Bài & Tài Liệu Mở Rộng
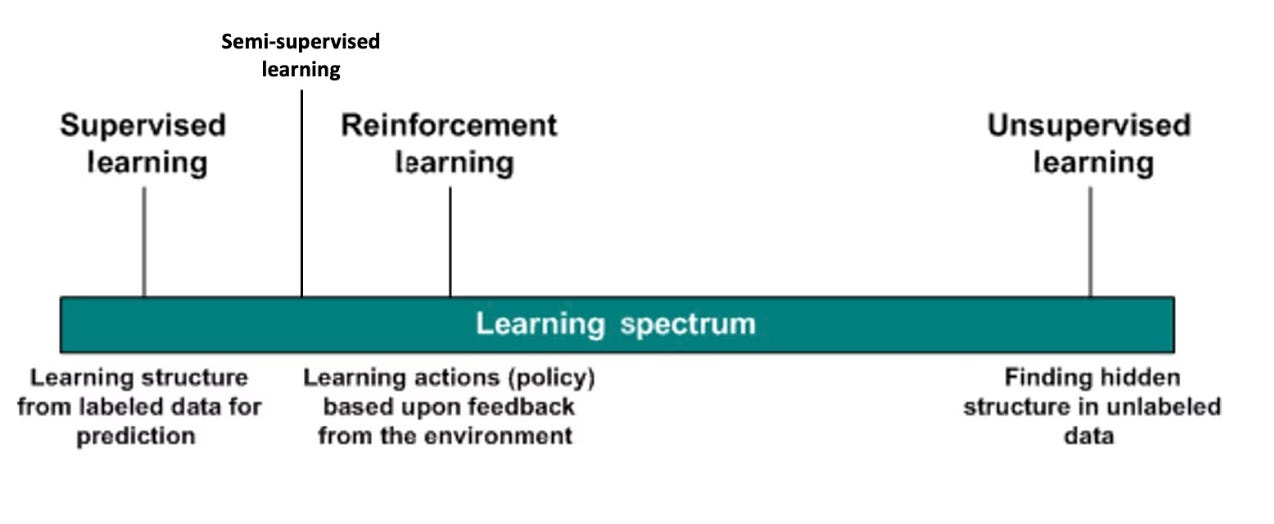
Vậy để tổng kết lại, có lẽ thật bất ngờ cũng như đầy ngỡ ngàng khi thế giới của Machine Learning không chỉ ngừng lại với những danh giới rõ ràng giữa Supervised Learning, Unsupervised Learning như nhiều người mới học đã nghĩ.
Thế giới của nó (ML) như một phổ màu không biên giới giữa 2 thái cực của SL và UL, và giữa chúng là một địa phận bí ẩn còn tiềm ẩn nhiều bí mật mà sự sáng tạo của các nhà khoa học vẫn chưa khai phá hết được - và SSL chỉ là một phần nhỏ trong phổ màu rộng lớn và đầy thú vị đến độ khó chịu, và ai biết được sau này các nhà khoa học sẽ tìm được thêm phát minh gì gây chấn động cả cộng đồng nghiêm cứu và học về ML nữa chứ 🫠.
Và để tặng bạn đọc cuối bài mình sẽ đính kèm một tấm ảnh mình đã sưu tầm về thế giới ML hiện tại - và một chút nguồn tài liệu để các bạn có thể tranh thủ tìm hiểu về chủ đề này trong lúc có thể đợi bài viết mới ra !
Cảm ơn bạn đã đọc đến đây nhé !
Good Luck, Daves Tran
Tài liệu mở rộng cho đọc giả:
van Engelen, J. E., & Hoos, H. H. (2019). A Survey on semi-supervised Learning. Machine Learning, 109, 373–440. https://doi.org/10.1007/s10994-019-05855-6
Teksands . (2021, October 26). Introduction to Semi-Supervised Learning | TeksandsAI. Teksands. https://teksands.ai/blog/semi-supervised-learning
Chaudhary, A. (2020, July 12). Semi-Supervised Learning in Computer Vision. Amit Chaudhary. https://amitness.com/posts/semi-supervised-learning
Neural Ninja. (2023, May 21). Expectation Maximization Clustering Algorithm: Unraveling Hidden Patterns - Let’s Data Science. Let’s Data Science. https://letsdatascience.com/expectation-maximization-clustering/
Liu, Y., Research, B., & Cruz, S. (2023). The Importance of Human-Labeled Data in the Era of LLMs. https://arxiv.org/pdf/2306.14910
Abney, S. (2002). Bootstrapping (pp. 360–367). https://aclanthology.org/P02-1046.pdf
Copyright Notice:
Copyright © 2024 Daves Tran