
Mở Đầu
Cứ khi có một bài báo hay nguồn nào trong giới truyền thông đại chúng nói đến Machine Learning (học máy - ML) , thì cụm từ mà sau đó tôi nghe thấy tiếp theo sau nếu không phải là bất cứ một “Umbrella Term - thuật ngữ ô dù” nào liên quan về AI (trí tuệ nhân tạo) hay Deep Learning (học với các mạng lưới Neuron - Neural Net như chatGPT), thì cụm từ tiếp theo sau đó lại khả năng cao liên quan đến Data - Dữ Liệu.
Đúng là Data là một phần rất “sống còn” trong quá trình phát triển các công cụ ML, nhưng phải thật đi sâu vào thì mới thấy câu chuyện về quá trình xử lý Data là một mảnh đất rất thú vị và còn nhiều điều chưa được kể hết - nhất là với các bạn mới bắt đầu trên con đường tiếp xúc với lĩnh vực Machine Learning hay các ngành liên quan đến Khoa Học Dữ Liệu (Data Science).
Giới thiệu tuy dài dòng như vậy - nhưng đó chỉ là một chút “Intro” về vai trò của Dữ liệu trong quá trình ML, và đúng như bạn đã đọc tiêu đề bài viết - hôm nay chúng ta sẽ bàn về Outlier (Các dữ liệu ngoại lai), và đây là một chủ đề thú vị nhưng do thời lượng không đủ nên tôi đành chia cả bài thành 2 phần. Và nội dung sơ bộ sẽ như sau:
Nội dung của Phần 1:
Outlier là gì và tại sao nó lại tồn tại !
Outlier là “kẻ xấu” hay “người hùng” ?
Nội dung của Phần 2:
Có những loại Outlier nào !
Có những cách nào để “làm việc” với Outlier không ?
#Note: Bài viết này chỉ là chia sẻ dưới dạng “Tóm tắt” và “Tổng kết” từ góc nhìn cá nhân của tác giả, nên có một số chi tiết đã được đơn giản hoá để phù hợp với số đông và chỉ có thể bào toàn một số ý tưởng (intuition) của lý thuyết, do đó có thể sai khác trong quá trình diễn giải.
Nếu bạn muốn tìm một số nguồn nói chi tiết hơn - thì bạn có thể tham khảo thêm các nguồn đọc thêm ở cuối bài (hoặc trích trong phần “caption dưới ảnh” để có thêm sự chính xác hơn.
Cảm ơn bạn đã đọc !
1.Outlier là gì và tại sao nó lại tồn tại !
Outlier Là Gì ?
Outlier (Dữ liệu ngoại lai) là gì ? - Câu hỏi này nhìn tưởng đơn giản nhưng cũng khá thú vị, vì có rất nhiều định nghĩa về kiểu dữ liệu này nhưng nhìn chung chúng ta có thể tóm tắt tất cả những gì tạo nên một Outlier hoàn hảo thành 1 phương trình dễ hiểu như sau:
OUTLIER = DATA + ABNORMALITY + SIGNIFICANT IMPACT
Có thể hiểu phương trình trên như sau:
Một Outlier phải là một điểm dữ liệu (DATA) trong một tập hợp các dữ liệu tương tự
Bên cạnh hành vi của Outlier phải có sự bất thường (ABNORMALTY). Cụ thể là không tuân theo một quy tắc mà các điểm khác trong tập cùng tuân theo. Một số ví dụ điển hình:
Không theo một quỹ đạo nào chung với phần lớn dữ liệu

Nó thường không đi cùng đường với số đông - Image Source: Worldfram MathWorld Không tuân theo dự đoán của bạn với giả thuyết nghiêm cứu.

Outlier không đi theo cùng quỹ đạo với phần lớn Dataset của bạn như bạn đã dự đoán - Image Source: Sergio Santoyo on Medium 
It’s so weỉrd ! - Image Source: Worldfram MathWorld Cuối cùng là có tầm ảnh hưởng đáng kể (SIGNIFICANT IMPACT) đến mức không thể không để ý được, và ảnh hưởng này có thể thể hiện qua:
Ngoại hình và hành vi mà toàn bộ tập dữ liệu bạn đã thu được (có thể qua khoảng cách bất thường giữa các điểm dữ liệu)

Tại sao có những mốc thời gian nhiệt độ lại thấp hơn nhỉ ? - Image Source: mathspace Hoặc ảnh hưởng của nó đến toàn bộ cấu trúc của mô hình (model) (như quá trình đưa ra quyết định hoặc xây dựng mô hình)
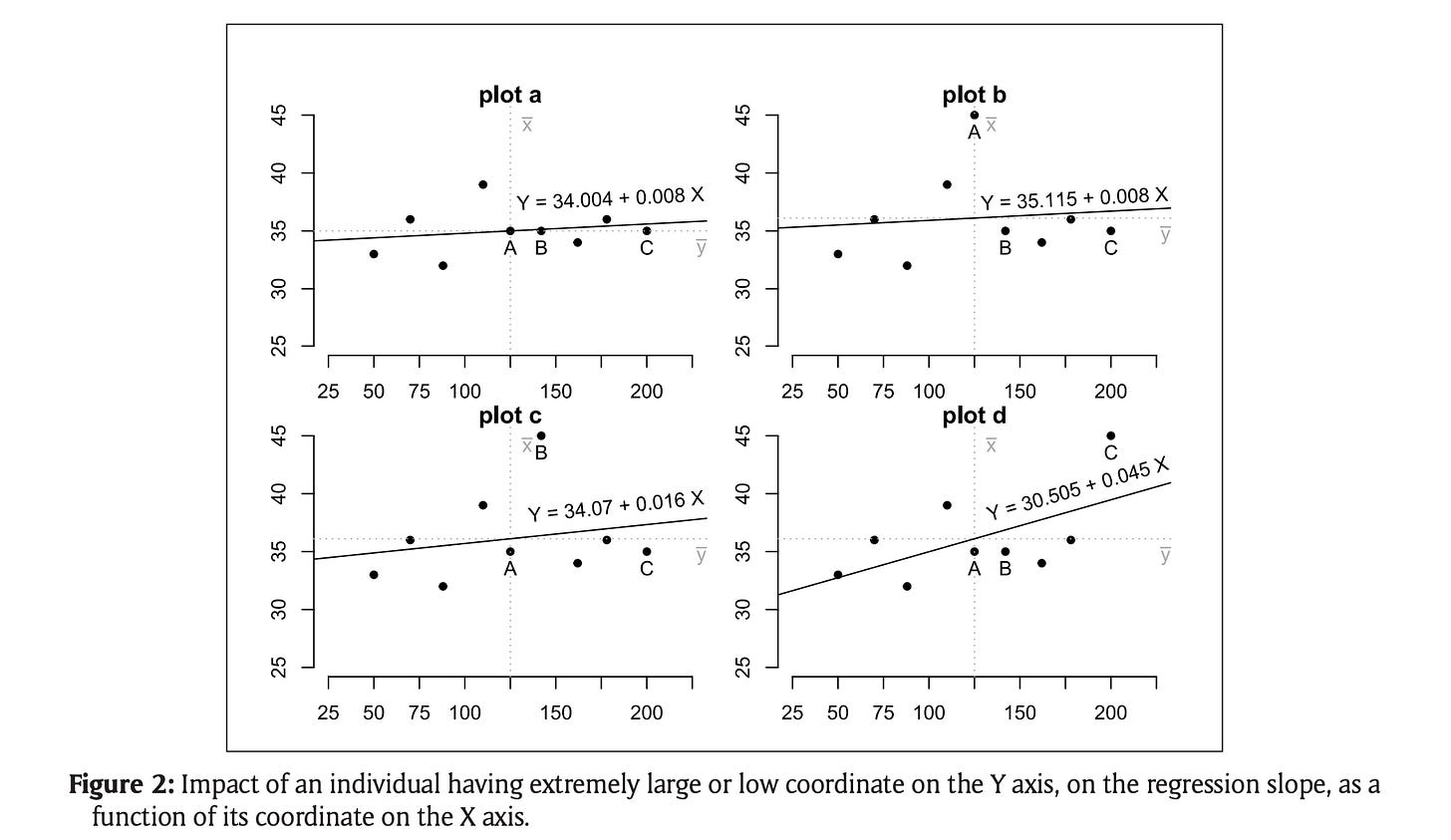
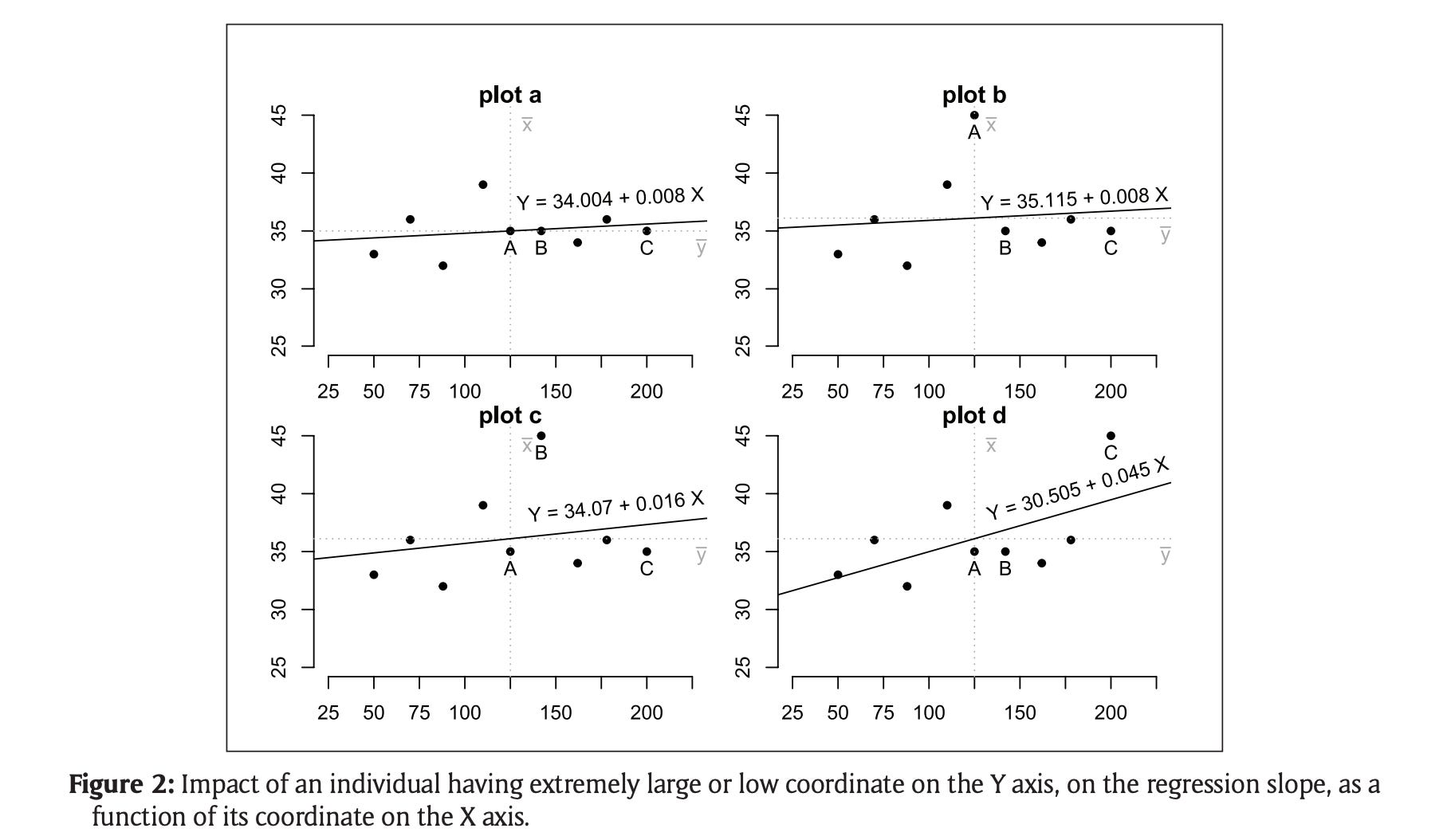
Mô hình hồi quy là một trong số nạn nhân “nặng nhất” của các Outlier - Image source: (Leys et al., 2019) 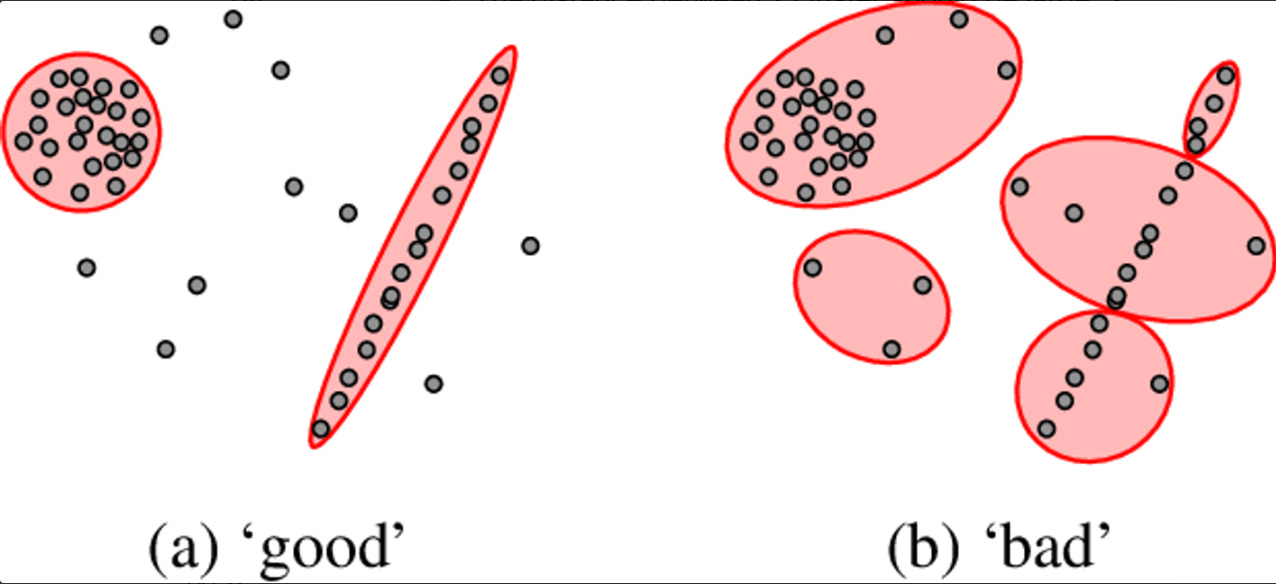
Bài toán Clustering cũng ảnh hưởng không hề ít bởi các Outliers - Image Source: Böhm, C. et al. “Robust information-theoretic clustering.” Knowledge Discovery and Data Mining (2006).




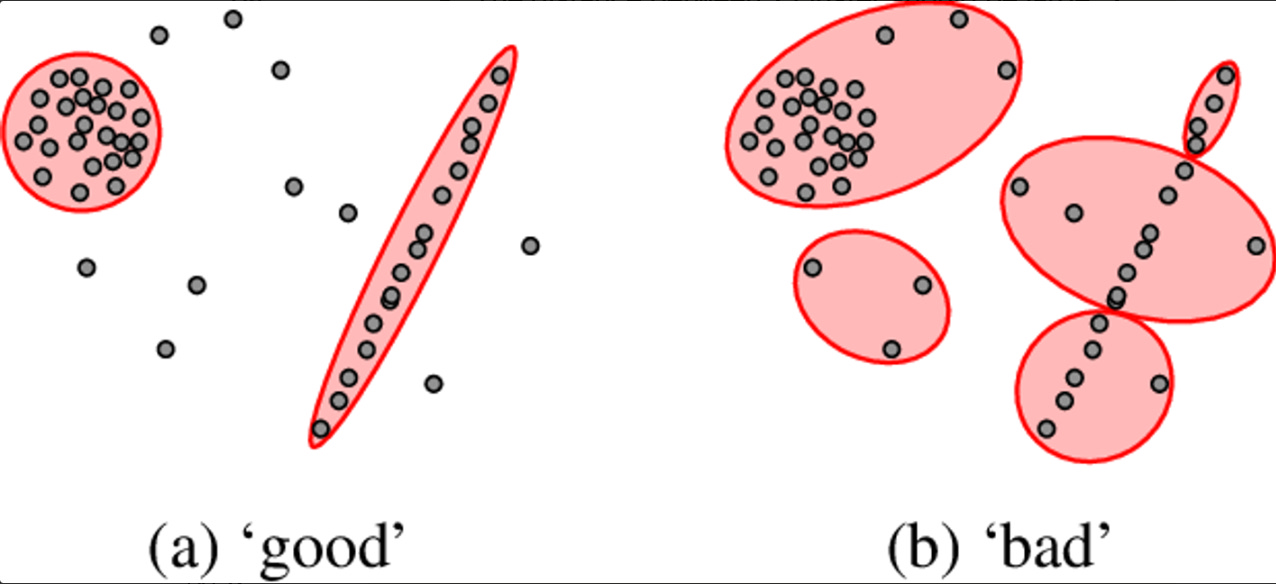
Tại Sao Outlier Lại Tồn Tại :
Vậy nếu Outlier gây ra cho chúng ta nhiều khó khăn trong quá trình giải các bài toán về ML (như hình ở bên trên) - vậy tại sao chúng lại tồn tại ? Liệu đó là kết quả của con người can thiệp, hay bản chất của population (tập lớn) thông qua quá trình chúng ta chọn lọc và lấy mẫu khai thác (Sampling).
Câu trả lời có lẽ chính xác nhất cho câu hỏi trên là cả hai (đó vừa là từ con người, nhưng trong một số trường hợp là bản chất tự nhiên của Population mà ta đang cần nghiêm cứu)
Vậy trước hết hãy nói về yếu tố Outlier là do con người - đối tượng thực hiện nghiêm cứu & xử lý dữ liệu nhé !
Trong các trường hợp sau Outlier có thể do con người gây ra:
Trường hợp một:
Do lỗi trong quá trình đo đạc - tiến hành thí nghiệm (sai số của dụng cụ thu thập)
Sai số trong quá trình xử lý dữ liệu (như vô tình lọc bỏ quá nhiều dữ liệu do sai sót)
Sai số trong quá trình thiết kế công cụ thu thập dữ liệu từ population - như hình thức trình bày làm cho việc thu thập bị thu thập sai dữ liệu hoặc gây ra hiện tượng Bias (thiên kiến) ngầm
Ví dụ tiêu biểu nhất có thể là số lượng vote giữa các bang tại Hoa Kỳ trong kỳ bầu cử Tổng Thống 2004 tại bang Ohio lớn bất thường do thiết kế của phiếu bầu làm người dân bầu cho sai ứng cử viên. (tham khảo tại đây: 2004 Election Error)
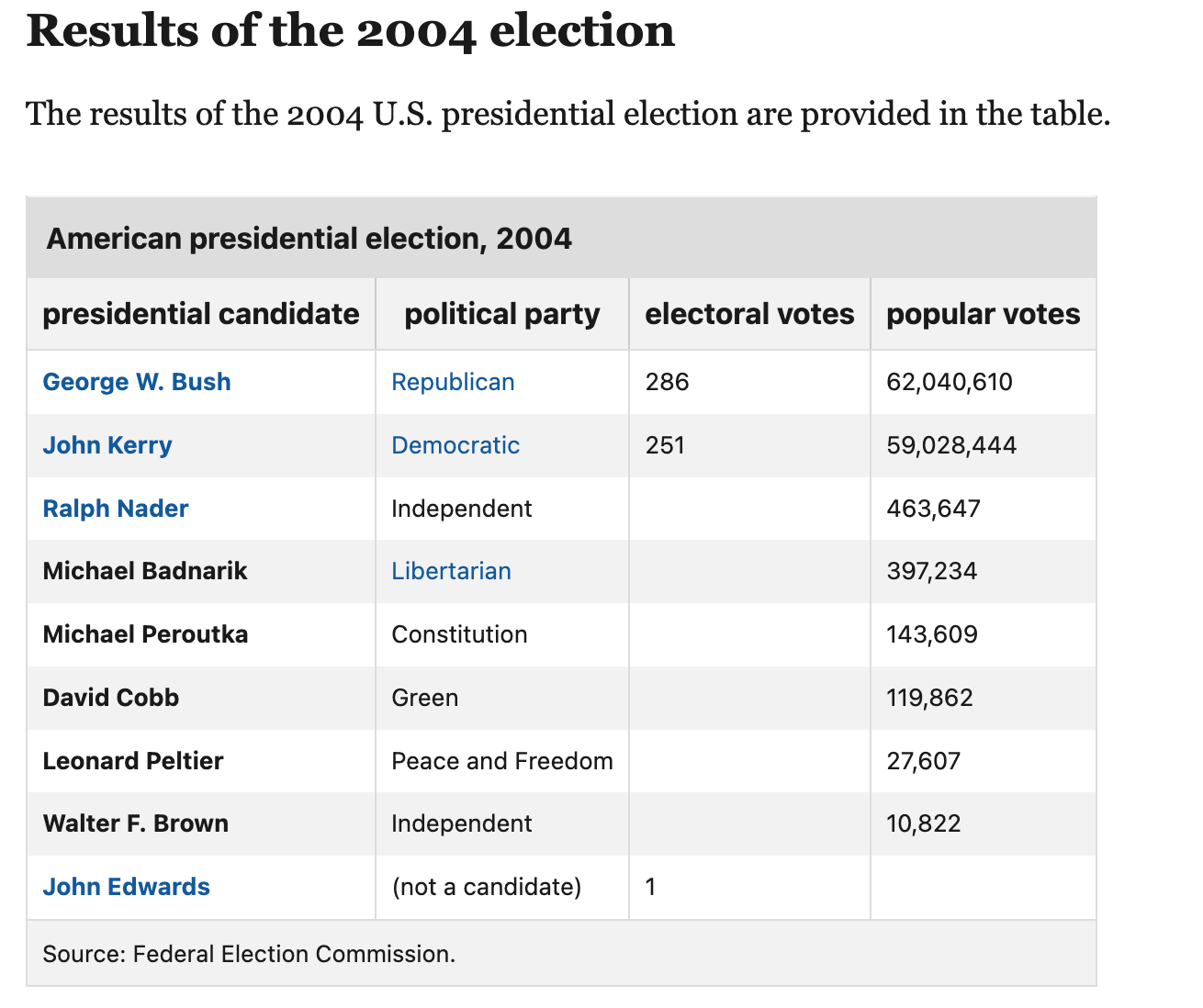
Image source: Britannica
Trường hợp hai:
Do người làm việc với bộ dữ liệu này thường cố ý dẫn Outlier vào, thường để check với các bài toán nhận diện đối tượng (Object Detection Problem), và có việc đưa outlier vào cũng là một cách tốt để check xem liệu mô hình cuả bạn có bị đưa ra quyết định có thiên kiến hay không
Có lẽ Google đã phải học bài học này về dữ liệu của học một cách khá là đắng khi thuật toán nhận dạng cuả họ lại đưa ra những quyết định phân biệt sắc tộc vì thuật toán chỉ phân biệt tốt với người da trắng, trong khi các outlier (các màu da tối hơn) lại đưa ra quyết định kém hơn - thậm trí tiêu cực 🚨
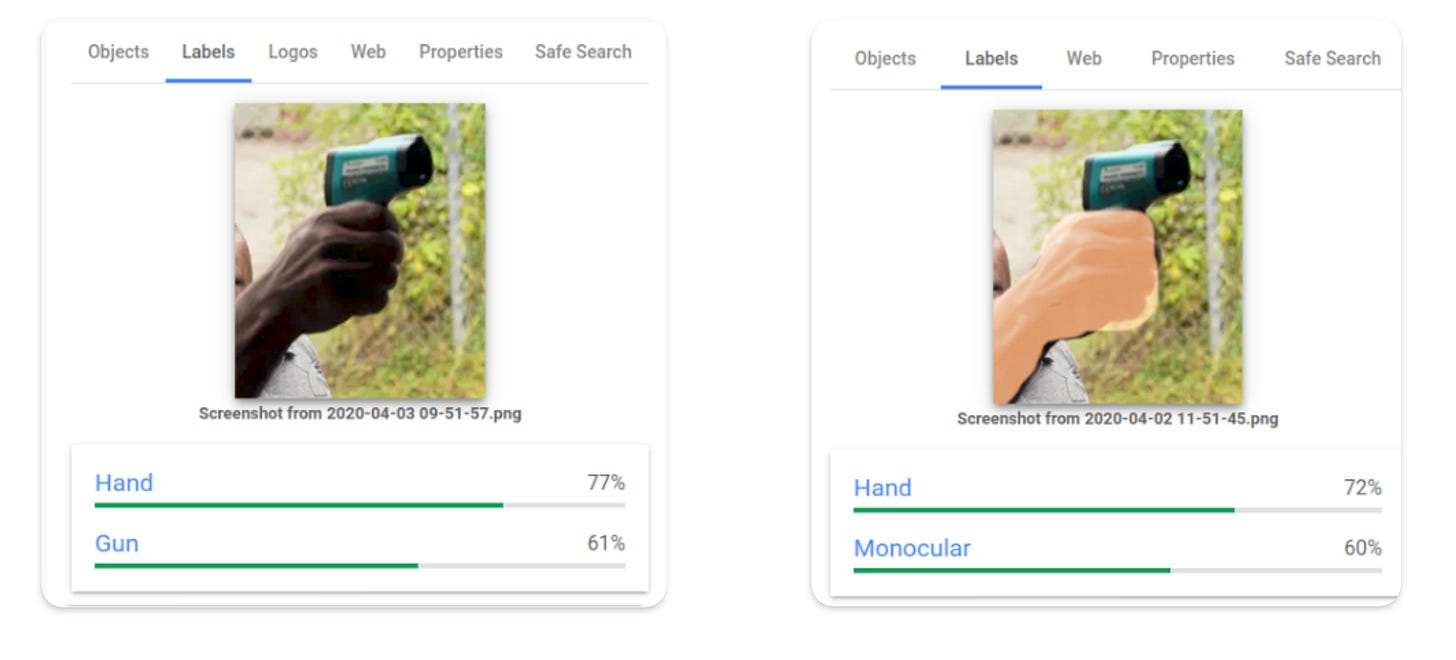
Câu chuyện của Google là một bài toán đau đầu mà Outlier gây ra chưa giải quyết được - Image Source: Algorithm Watch
Trong các trường hợp sau Outlier lại gây ra bởi bản chất của Population (Tập lớn) mà chúng ta muốn nghiêm cứu - Natural Outliers:
Với các tình huống này - tuỳ vào lĩnh vực nghiêm cứu thì sẽ có những lời giải thích khác nhau và lý do tại sao Outlier tồn tại lại không phải là câu chuyện của ML và xác xuất thống kê mà còn do bản chất của Population và lĩnh vực bạn đang nghiêm cứu.
Một ví dụ cụ thể là: Tại sao trong một lớp học tại một trường ở tỉnh A , lại có một số lượng lớn hiện tượng bạo lực học đường, trong khi khi so sánh với các tỉnh còn lại thì tỉ lệ bạo lực lại thấp hơn đáng kế

Something interest may hide under Outliers - Image Source: Sermon from a Psycho Để có thể trả lời câu hỏi trên về tình trạng Outlier trên thì đó không chỉ còn dừng ở vấn đề về phân tích thống kê hay ML, mà phải thực hiện các nghiêm cứu sâu trực tiếp và cần nhiều kinh nghiệm chuyên môn (tâm lý học đường, chính sách giáo dục giữa tỉnh A với các tỉnh khác, etc.) để tìm được mô hình giả thuyết giải thích hiện tượng trên.

2.Outlier là “Kẻ xấu” hay “Người hùng” ?
Nếu nghe những mô tả về Outlier thuộc phần trên các bạn đọc khả năng cao sẽ nghĩ Outlier là một “kẻ phản diện” không mời mà đến trong dataset của chúng ta và nó đáng bị loại bỏ, nhưng tôi không nghĩ như vậy.
Nếu để có một lời phân xử cho việc Outlier là Hero hay Villian thì tôi sẽ mượn tạm bài báo của Christophe Leys và đồng sự vào năm 2019 để phân tích:
Trong bài Leys có nhắc đến là Outlier vừa là một kết quả cuả con người nhưng cũng là một phần rất tự nhiên của rất nhiều quần thể mà chúng ta muốn tìm hiểu và nghiêm cứu (như trong nội dung của phần 1 của bài này), và việc “Giữ hay Bỏ - Keep or Kill” với Outlier là một tình huống tương đối là khó để xác định được.
Trường hợp: nếu Outlier là một “Người Hùng” 😇:
Tức là đằng sau những kẻ ngoại lai này lại ẩn chứa thông tin thú vị về quần thể của chúng ta đang nghiêm cứu (Theoretical Interest - Leys 2019), thì việc loại bỏ chúng thì khiến cho bộ dữ liệu (mẫu) của chúng ta dường như mất đi tính đa dạng và sự đại diện cho toàn bộ quần thể.
Bạn cứ thử tưởng tượng như một trường cấp ba chỉ có bao gồm Người Kinh (mẫu bạn làm nghiêm cứu đã loại bỏ outlier), nhưng so với các trường khác tại Việt Nam lại là một tổ hợp của nhiều dân tộc thiểu số từ Tày, Sán Chỉ, etc (các outlier là các học sinh dân tộc thiểu số)

54 Dân Tộc Việt Nam - Image Source: Saigoneer
Việc loại những Outlier này lại làm tăng khả năng bị dính lỗi Dương Tính Giả (False Positive) trong việc đưa ra quyết định liên quan đến giả thuyết của bạn - bạn nói “không”, trong khi câu trả lời của bạn lại đúng 🙌🏻.
Trường hợp: nếu Outlier là một “Phản Diện” 👿:
Có thể bạn nghĩ Outlier trong tình huống này có ẩn ý sâu sa liên quan đến đối tưởng nghiêm cứu (Theoretical Interest) nên đành không loại bỏ chúng khỏi bộ dữ liệu, hoặc trong quá trình bạn xử lý dữ liệu thô thì lại bị phá bĩnh bởi chúng mà không để ý.
Nhưng trong trường hợp này giữ lại Outlier thì chỉ khiến kết quả của mô hình đưa ra bị sai bởi bộ dữ liệu hoàn toàn có thể bị dính bias do các outlier (nhất là mô hình hồi quy - Regression , hay các bài toán Clustering)
Bên cạnh giữ lại các outlier không chỉ làm mẫu (Sample) không chỉ mất đi tính đại diện cho quần thể lớn, mà còn tăng khả năng lỗi Âm Tính Giả (False Negative) - giả thuyết hoặc kết quả của bạn sai nhưng mà bạn lại không bác bỏ nó còn sử dụng và công nhận kết quả đó 😟.

Image Source: Economic Stack Exchange Chính bởi việc không biết khi nào nên giữ, khi nào nên diệt Outliers khỏi bộ Dataset có phần làm cho bài toán xứ lý Outlier là một vấn đề rất là khó nhằn - nhưng để có thể tóm tắt tầm quan trọng của bài toán này thì bạn có thể nhìn bức ảnh mà tôi đã cung cấp bên trên và nhìn thử mô hình sau:

Để biết thảm hoạ do ML gây ra thế nào, thì bạn có thể tìm kiếm cụm từ khoá “AI Disasters” hoặc “ML Disasters” (dịch: Các thảm hoạ gây ra bởi Trí tuệ nhân tạo (AI) và hệ thống Machine Learning)



Lời Bình Cuối Bài & Tài Liệu Mở Rộng
Tổng kết lại Phần 1 về Outlier, thì dưới góc nhìn cá nhân, vấn đề về xử lý các dữ liệu ngoại lai là một câu chuyện tuy tưởng chừng là đơn giản - chỉ có xung quanh 2 chữ “Bỏ và Giữ”, nhưng cũng tiềm ẩn rất nhiều điều thú vị và bài toán chưa được giải quyết. Tôi thấy có lẽ là một trong số những lý do mà vấn đề dữ liệu luôn chưa bao giờ là chủ đề hết nóng trong cộng đồng nghiêm cứu và Machine Learning và cả một nền công nghiệp mới về dữ liệu với những công việc mới về Data như Data Analysis hay Data Science bùng nổ.
Trong phần tiếp theo của bài viết chúng ta sẽ cùng tìm hiểu kỹ hơn về những kỹ thuật ML để có thể xử lý Outliers và biết cách phân loại các loại Outlier, và cuối bài vẫn sẽ là một chút tài liệu mở rộng cho bạn đọc để tìm hiểu thêm !
Cảm ơn bạn đã đọc đến đây nhé !
Good Luck, Daves
Tài liệu mở rộng cho đọc giả:
Leys, C., Delacre, M., Mora, Y. L., Lakens, D., & Ley, C. (2019). How to Classify, Detect, and Manage Univariate and Multivariate Outliers, With Emphasis on Pre-Registration. International Review of Social Psychology, 32(1). https://doi.org/10.5334/irsp.289
Copyright Notice:
Copyright © 2024 Daves Tran